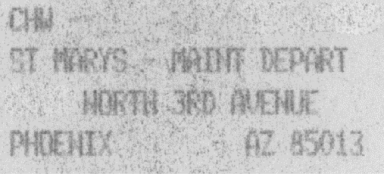AccuReadTM OCR omogućava upotrebu značajke za optičko prepoznavanje znakova (OCR) višenamjenskog uređaja (MFP) prilikom digitalizacije dokumenata, što ima sljedeće prednosti:
Upotreba aplikacije za izradu datoteka koje se mogu pretraživati i uređivati iz fizičkih dokumenata. Za razliku od tradicionalnih računalnih OCR rješenja, AccuRead OCR kombinira skeniranje i OCR u jedinstveni proces. Aplikacija ne zahtijeva instalaciju TWAIN ili ISIS (Image and Scanner Interface Specification) upravljačkih programa ili pak podešavanje odredišnog skeniranja.
| Napomena: Razlučivost skeniranja za OCR zaključana je na 300 dpi radi postizanja boljih rezultata prepoznavanja. Temeljitim testiranjem utvrđeno je kako se skeniranjem pri 300 dpi postiže značajno veća preciznost no skeniranjem pri nižim razlučivostima. Skeniranjem pri razlučivostima iznad 300 dpi nisu utvrđena daljnja poboljšanja. |
Radne karakteristike OCR-a
Radne karakteristike AccuRead OCR-a mjere se vremenom koje je potrebno za skeniranje dokumenta sve dok ne primite konačni digitalni rezultat.
Tvrtka LexmarkTM pregledala je testne pakete koje su izradile organizacije za standarde kao što su Međunarodna organizacija za standardizaciju (ISO) i Međunarodna elektrotehnička komisija (IEC) te je odabrala ISO/IEC 24735. U sklopu tog paketa, testiranje je izvršeno s crno-bijelim skenovima i skenovima u boji, na višenamjenskom uređaju CX720 s 4GB RAM memorije i tvrdim diskom.
Ogledne slike uključene u testni paket | |
| |
Uvjeti za testiranje skeniranja bili su sljedeći:
Za sva skeniranja koristili smo dokumente od 1, 10 i 25 stranica.
Skeniranja smo ponavljali nekoliko puta kako bi se osigurala točnost rezultata.
Crno-bijeli skenovi postavljeni su na tonove sive.
Postavke za svaki od skenova obuhvaćale su automatski ulagač dokumenata, jednostrani ispis, format Letter te kombinaciju teksta i fotografije.
Koristili smo skeniranje na flash pogon sa zadanim postavkama.
Prosječni rezultati testiranjaVrsta skeniranja | Rezultati radnih karakteristika |
Crno-bijelo skeniranje | 3–6 sekundi po stranici |
Skeniranje u boji | 4–7 sekundi po stranici |
Ogledni dokumenti
AccuRead OCR najbolje funkcionira s dokumentima kod kojih postoji velik kontrast između teksta i pozadine.
Dokumenti s malim kontrastom između teksta i pozadine ili pak oni kod kojih se koriste svijetla i tamna boja fontova zahtijevaju napredniju obradu. Preciznost OCR-a može se povećati podešavanjem postavki skeniranja ili upotrebom poslužiteljskog OCR rješenja.
Dokumenti koji nisu idealni za AccuRead OCR ili poslužiteljski OCR uključuju sljedeće:
Slike s previše šuma koji je bojom sličan tekstu
Slike s tamnim tekstom na tamnoj pozadini
Svijetle slike s matričnim znakovima