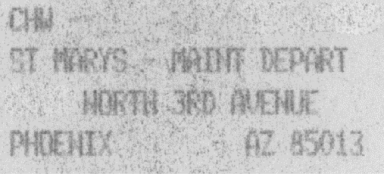AccuReadTM OCR позволяет выполнять распознавание символов (OCR) на МФУ для оцифровки документов, обеспечивая следующие преимущества:
Оптимизация управления документооборотом благодаря использованию функций поиска и редактирования
Повышение производительности
Снижение ошибок
Сокращение времени обработки
Использование современных технологий
Используйте приложение для создания файлов документов с возможностью поиска или редактирования из печатных документов. В отличии от традиционных решений OCR для настольных систем приложение AccuRead OCR объединяет процесс сканирования и оцифровки (OCR) в один процесс. Для приложения не требуется установка драйверов TWAIN или спецификации ISIS, или корректировка объектов сканирования.
| Примечание. Разрешение сканирования функции OCR заблокировано на значении 300 dpi для обеспечения работы функции распознавания. Опытным путем выявлено, что при разрешении 300 dpi точность распознавания значительно выше, чем при более низком разрешении. При сканировании с разрешением выше 300 dpi не было выявлено никаких преимуществ. |
Производительность функции OCR
Производительность приложения AccuRead OCR измеряется как затраченное время, начиная со сканирования и до получения цифрового документа.
Компания LexmarkTM рассмотрения наборов тестов, созданных такими организациями по стандартам, как Международная организация по стандартам (ISO) и Международная электротехническая комиссия (МЭК), выбрала ISO/IEC 24735. С помощью данного набора производилось тестирование черно-белых и цветных заданий сканирования на МФУ CX720 с ПЗУ 4 ГБ и жестким диском.
Примеры изображений, включенных в наборы тестирования | |
| |
Условия тестирования были следующими:
В всех заданиях сканирования были 1-стр., 10-стр. и 25-стр. документы.
Задания сканирования выполнялись по несколько раз для обеспечения воспроизводимости результатов.
Для черно-белых заданий сканирования был задан режим оттенков серого.
Для всех заданий сканирования было задано: подача из устройства автоматической подачи документов, односторонняя печать, формат Letter и смешанный тип текст/фото.
Использовалось сканирование с сохранением на флэш-накопитель.
Усредненные результаты сканированияТип сканирования | Результаты тестирования производительности |
Черно-белое сканирование | 3–6 с на страницу |
Цветное сканирование | 4–7 с на страницу |
Примеры документов
Приложение AccuRead OCR работает лучше с высококонтрастными документами (контраст между текстом и фоном).
Для низкоконтрастных документов (контраст между текстом и фоном) или документов с темным и светлым текстом требуется более сложная обработка. Точность распознавания символов (OCR) можно повысить настройкой параметров сканирования или с помощью серверных решений OCR.
Следующие типы документов плохо подходят как для приложения AccuRead OCR, так и для серверных решений OCR:
Документы со значительными помехами, схожими по цвету с текстом
Документы с темным текстом на темном фоне
Светлые документы с точечными матричными символами